Related Work
Public Datasets
Spine Dataset by BioMedia Research Group
Source: https://biomedia.doc.ic.ac.uk/data/spine/
- Centroid of vertebrae is labeled
VerSe: Large Scale Vertebrae Segmentation Challenge
Source: https://github.com/anjany/verse
- Dataset with segmentation masks
- Advantages
- Already labeled
- Precise Segmentation masks
- Disadvantage:
- Not only thoracic / lumbar scans
- Different variability in data: field-of-view, fractures, transitional vertebrae, etc.
AASCE 2019
Source: https://aasce19.grand-challenge.org
- Estimation of spinal curvature
- Data not for sure helpful, but research approaches are related
Detecting Vertebrae of the Spine
Vertebra-Focused Landmark Detection for Scoliosis Assessment
Source: Yi J. et al. Vertebra-Focused Landmark Detection for Scoliosis Assessment. ISBI (2020)
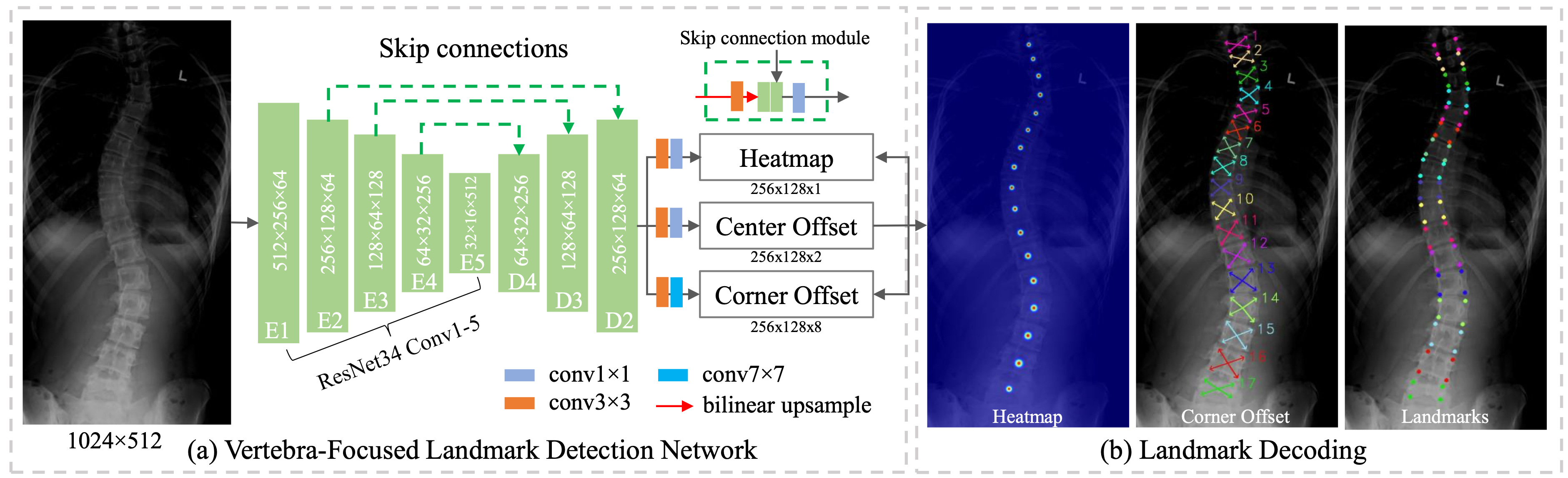
(a)The framework of the vertebra-focused landmark detection network. (b) Landmark decoding process. The vertebrae centers are extracted from the heatmap and the center offset. From the center of each vertebra, the four corner landmarks are traced using the corner offset.
Idea / Concept
- Vertebra-focused landmark detection method based on keypoint detection
- Localize the vertebrae centers
- Heatmap of Center Points: A 2D Gaussian disk is used as ground truth of each center point
- Center Offset: Center points are extracted from downsized feature map, center offset is used to map the points back to the original input image
- Trace the four corner landmarks of the vertebrae through the learned corner offset (regress corners using convolutional layers)
- Localize the vertebrae centers
- Claimed advantages:
- regression-based methods for the vertebrae landmark detection typically suffer from large dense mapping parameters and inaccurate land- mark localization
- segmentation-based methods tend to predict connected or corrupted vertebra masks
- Problem of adapting this approach
- Difference view (front instead of side)
- Always the same 17 vertebrae detected
- Code available on GitHub
Take-Away
- Keypoint detection could work better than regression or segmentation
Vertebrae Detection and Localization in CT with Two-Stage CNNs and Dense Annotations
Idea / Concept
- Two staged approach:
- Detect where the vertebrae appear in the scan using 3D samples (segment the vertebrae from the background)
- Identify the specific vertebrae within that region-of-interest using 2D slices (identifies which pixels belong to which vertebra)
- does not classify each pixel discretely but instead produces a continuous value for each pixel. This value is then rounded to an integer which corresponds to a specific vertebra
- Multiply the results of the detection model and identification model to produce a labelling on each pixel
- Aggregate predictions to produce final centroid estimates for each vertebra
- Find the median position of all pixels which vote for each vertebra
- Filter out votes for pixel if number of votes below a threshold (threshold based on vertebra radius)
- Data preprocessing: Used dataset had only centroid positions (sparse labels) which had to be converted to dense labels. Solved with new algorithm:
- Find midpoints between all adjacent centroids in the column.
- Draw line segments between these midpoints. Add additional line segments at the start and end of the column so that there is a line segment to represent each vertebra.
- Plot discs (on the plane of the sagittal and transverse axes) around each point on the line segment. The radius of these discs is specific to the vertebra the line segment represents.
- Code available on GitHub
Take-Away
- Regression of centroid position does not work well on pathological cases -> turn regression problem into dense classification problem
-
This was done by generating a dense labelling, which is a label given to each pixel in the scan, from the ground-truth centroid annotations. The dense labelling is then converted back to the sparse labelling of centroid positions at the end of the processing pipeline.
-
- To detect vertebrae: Use multiple cropped samples per scan if not enough memory or to speed up training
- Large slices which capture long-range information are essential for identifying individual vertebrae
- Data augmentation: elastically deform samples
Automatic Lumbar MRI Detection and Identification Based on Deep Learning
Idea / Concept
- Does not distinguishing vertebras using annotated lumbar images, but compares similarities between vertebras using a beforehand lumbar image
- Input are two different images: a search image (the image to find the vertebras) and a contrast image (with a bounding box of S1 and another for L1-L5)
- Compare contrast image with search image to find S1 in the search image
- Compare contrast image with search image to find L1-L5
- Input are two different images: a search image (the image to find the vertebras) and a contrast image (with a bounding box of S1 and another for L1-L5)
- Due to its distinctive shape, S1 is firstly detected and a rough region around it is extracted for searching for L1–L5
- Trained on MRI, not on CT scans
Take-Away
- Use prior knowledge: It can be helpful to first search for vertebrae with high recognisability (i.e. S1) and then continuously expand the search field from there.
- Compare cropped views with a global view -> e.g. Compare thoracic / lumbar scans with complete scan?
Segmentation and Identification of Vertebrae in CT Scans Using CNN, k-Means Clustering and k-NN
- Combination of Deep Learning and classical Machine Learning for the tasks of vertebrae segmentation and identification
- Binary segmentation of whole spine using Deep Learning (3D convolutional)
- Semi-automated procedure to locate vertebrae centroids using traditional machine learning algorithms
- k-Means detects the individual vertebrae (split the binary segmentation masks into segmentation per vertrbrae)
- Advantage: Does not require single vertebrae-level annotations for trained - However, this only works if the number of vertebrae as well as the vertebrae labels are known
Body Composition Analysis (based on Segmentation)
- Lee et al., "Deep neural network for automatic volumetric segmentation of whole-body CT images for body composition assessment"
- Body composition segmentation (skin, bone, muscle, abdominal visceral fat, subcutaneous fat, internal organs with vessels, and central nervous system)
- Dataset: 46,967 image slices from 100 scans for training, 13,227 image slices from 64 scan for testing -> only 3,763 slices from 24 scans publicly available (French public dataset)
- Koitka et al., "Fully automated body composition analysis in routine CT imaging using 3D semantic segmentation convolutional neural networks"
- Multi-resolution U-Net 3D neural networks were employed for segmenting abdominal cavity, bones, muscle, subcutaneous tissue, and thoracic cavity, followed by subclassifying adipose tissue and muscle using known Hounsfield unit limits.
- Dataset: 40 CTs for training and 10 CTs for testing were fully annotated on every fifth axial slice -> not publicly available
- Ma et al., "Comprehensive Validation of Automated Whole Body Skeletal Muscle, Adipose Tissue, and Bone Segmentation from 3D CT images for Body Composition Analysis: Towards Extended Body Composition", CVPR 2021
- Segmentation of the bony tissue, the skeletal muscle, subcutaneous and visceral fat.
- Dataset: "Ground truth segmentation labels were manually generated by a team of trained anatomists using the semi-automatic segmentation tools using an in-house manual segmentation platform. Four tissue types were generated: 1) skeletal muscle (SKM) 2) bone; 3) subcutaneous adipose tissue (SAT), and 4) the visceral adipose tissue (VAT). On average, it took two weeks for each trained anatomist to carefully delineate these tissues manually for each volume highlighting the enormous time and skill that such measurements require."
- Fu et al., "Automatic segmentation of CT images for ventral body composition analysis", IVP 2020
- Segmentation of subcutaneous adipose tissue (SAT), visceral adipose tissue (VAT), muscle, cavity, lung and bones
- Dataset: A total of 60 CT scans were used, 30 CTs with oral and/or intravenous (IV) contrast were obtained from institutional archives and were from individuals without evidence of malignancy in the ventral cavity or surgical manipulation. The other 30 CT, 15 with IV contrast and 15 without IV contrast, were from The Cancer Imaging Archive (TCIA) with collection IDs of ‘TCGA-KIRC24' and ‘QIN- HEADNECK'12.