Results
The audio files from the TIMIT dataset were converted to Mel-spectrograms. Fixed length segments were then extracted from these Mel-spectrograms using a sliding window. The segments were split into two parts: The first part was fed into the model and used to predict the second part of the segment. This process is illustrated in below figure 2.
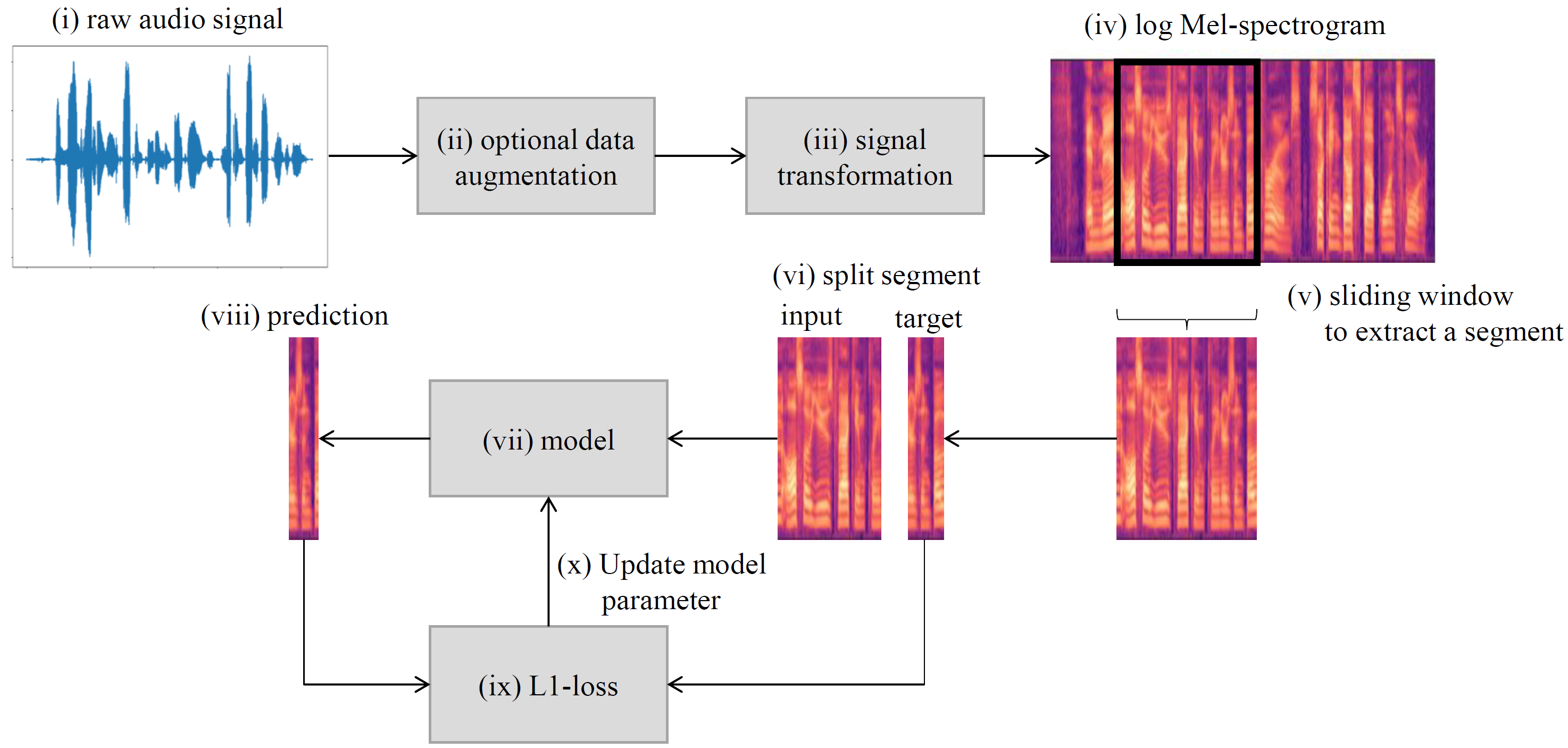
Figure 2: Concept of the trained network
Some results are presented below. In these models, 120 frames were fed into the network and 25 frames were predicted. After that, the sliding window was shifted forward by 1 frame and the process was repeated. The 25 predicted frames correspond approximately to one word. However, the quality of the prediction is difficult to determine based on only one word. Therefore, several predictions were composed.
The composition was done as follows: From a predicted sequence, the frame at the position offset was stored. Then the sliding window was moved shifted by 1 and the next frame at the position offset was saved.
The prediction becomes of course more difficult if the offset is larger. For example, with an offset=25, 24 frames must first be predicted and then only the 25th predicted frame is stored. With a smaller offset less frames have to be predicted and thus the task becomes easier.
The results are presented below. Only the ground truth and the prediction are shown in the table -> the segment that was fed into the network is not visible.
Speaker MRJM4, Sentence SA1
Ground truth audio (resynthesized Mel-spectrogram):
offset | Ground Truth spectrogram | Predicted Spectrogram | Predicted Audio |
|---|---|---|---|
| 1 | 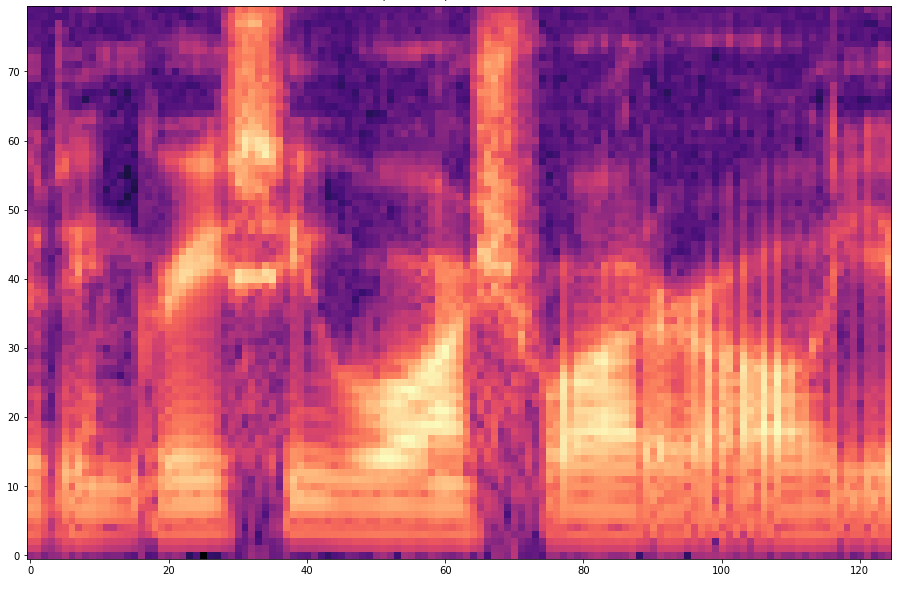 | 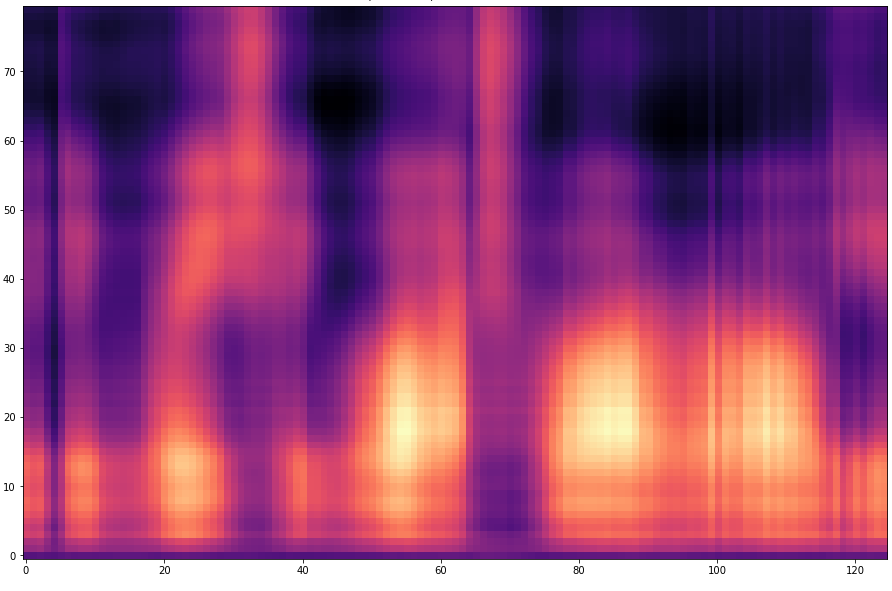 | |
| 5 | 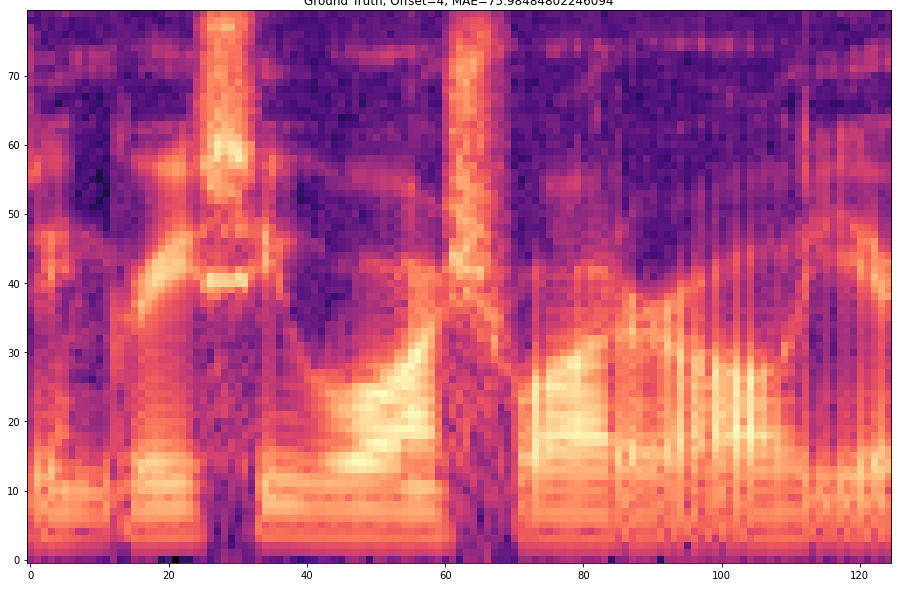 | 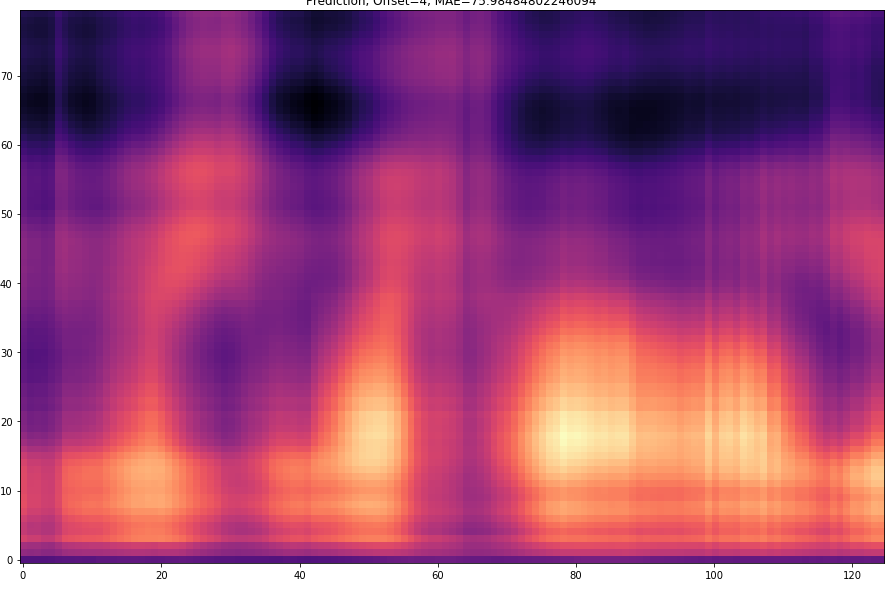 | |
| 10 | 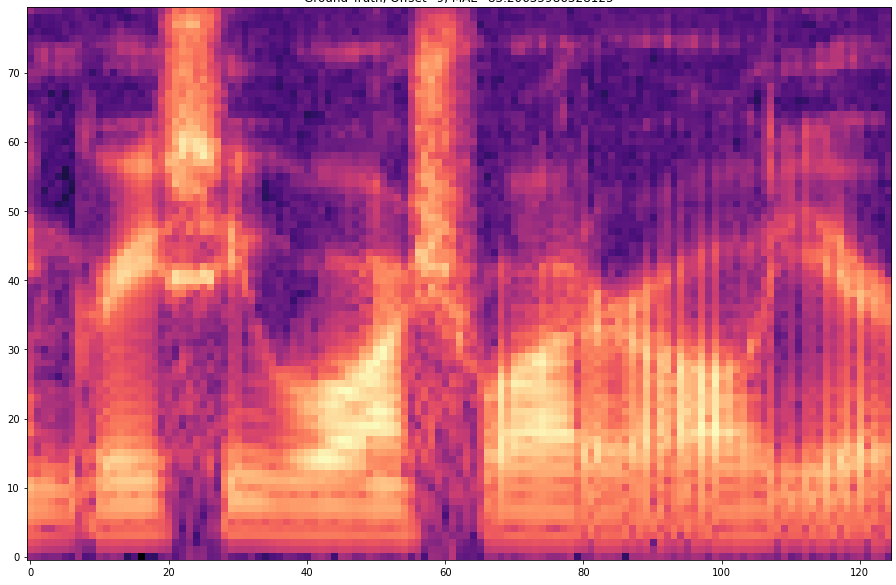 | 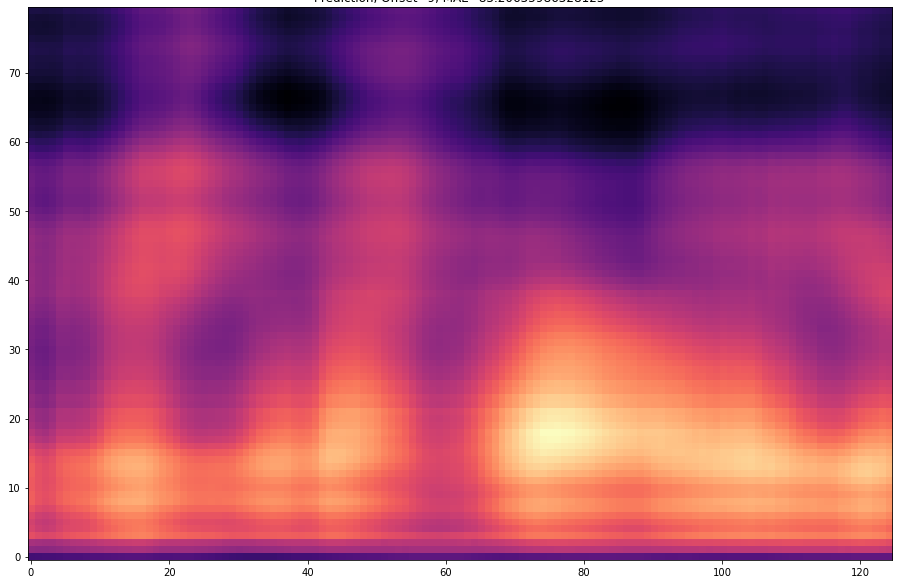 | |
| 20 | 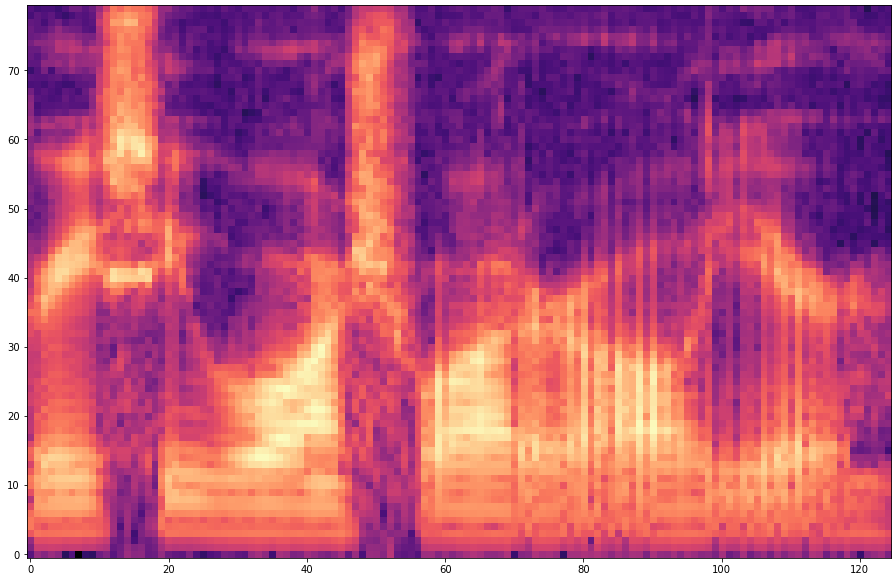 | 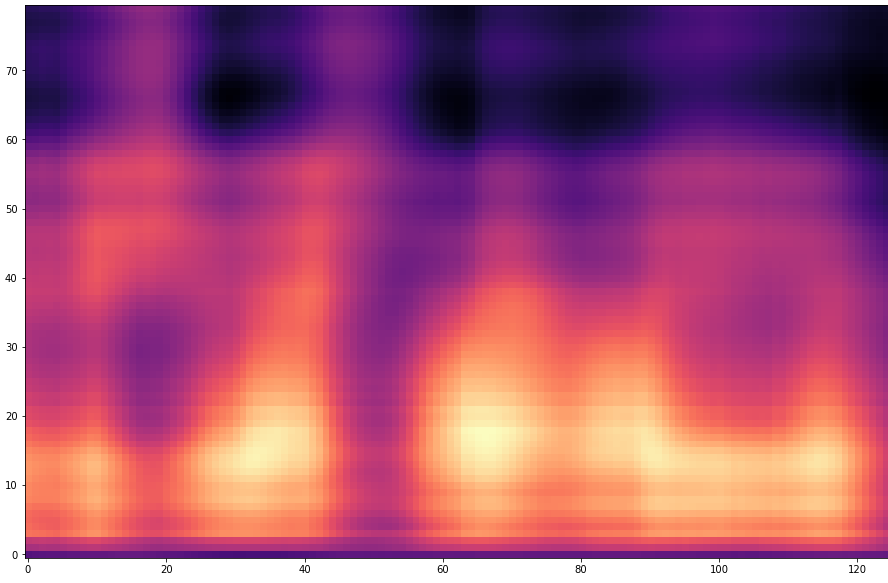 | |
| 25 | 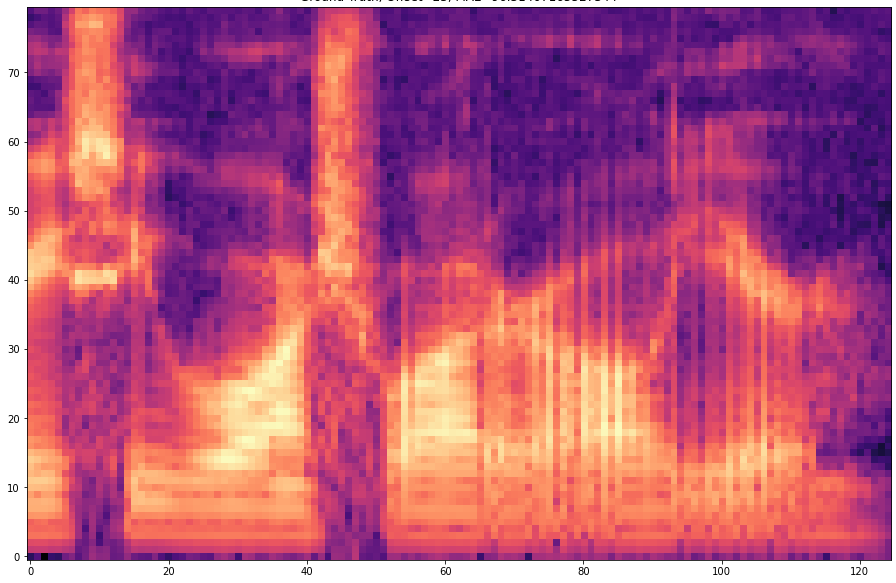 | 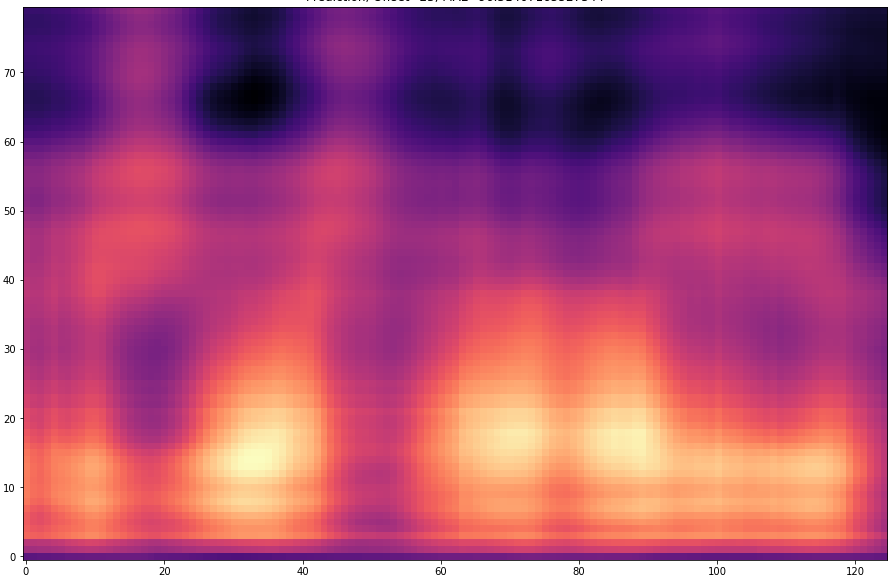 |
Speaker MJTH0, Sentence SA1 (Overfitted Model)
This model overfitted on the test data - but is for some sentences (such as this one) particularly good
Ground truth audio (resynthesized Mel-spectrogram):
offset | Ground Truth spectrogram | Predicted Spectrogram | Predicted Audio |
|---|---|---|---|
| 1 | /1-ahead_gt.png) | /1-ahead.png) | |
| 5 | /5-ahead_gt.png) | /5-ahead.png) | |
| 10 | /10-ahead_gt.png) | /10-ahead.png) | |
| 20 | /20-ahead_gt.png) | /20-ahead.png) | |
| 25 | /25-ahead_gt.png) | /25-ahead.png) |
Speaker MCHH0, Sentence SA2
Ground truth audio (resynthesized Mel-spectrogram):
offset | Ground Truth spectrogram | Predicted Spectrogram | Predicted Audio |
|---|---|---|---|
| 1 | 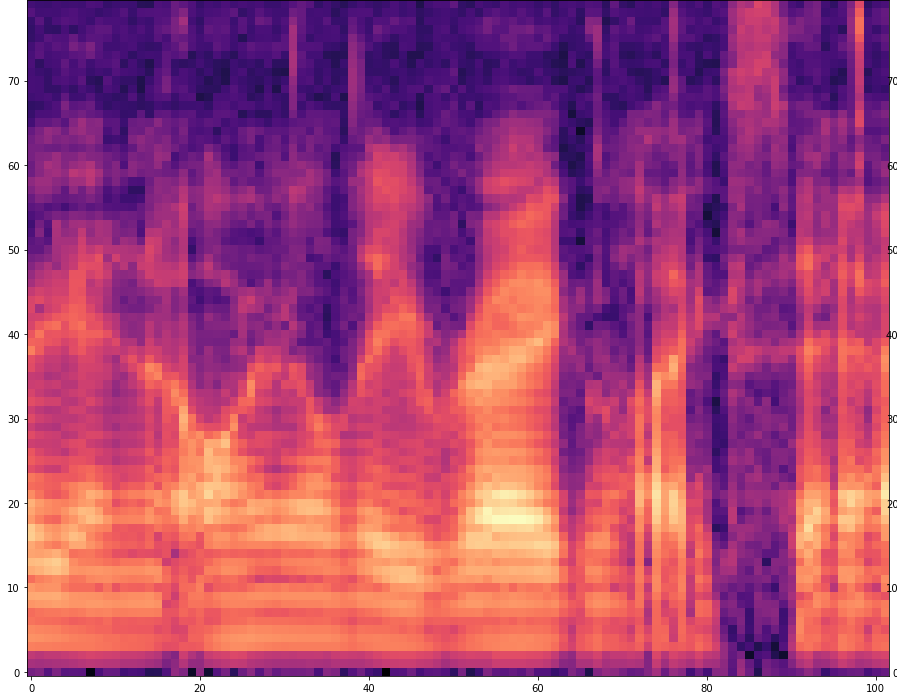 | 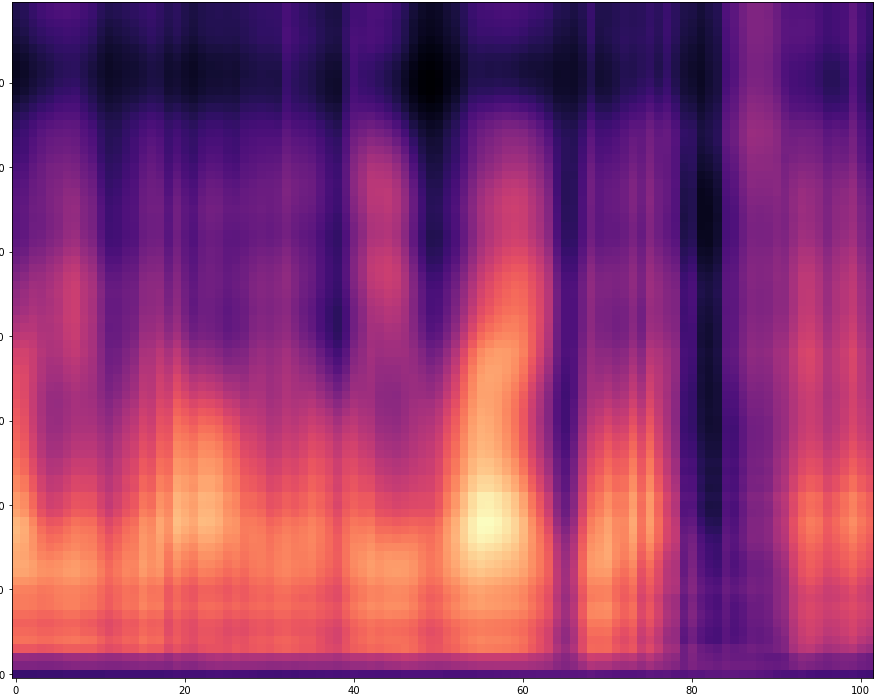 | |
| 5 | 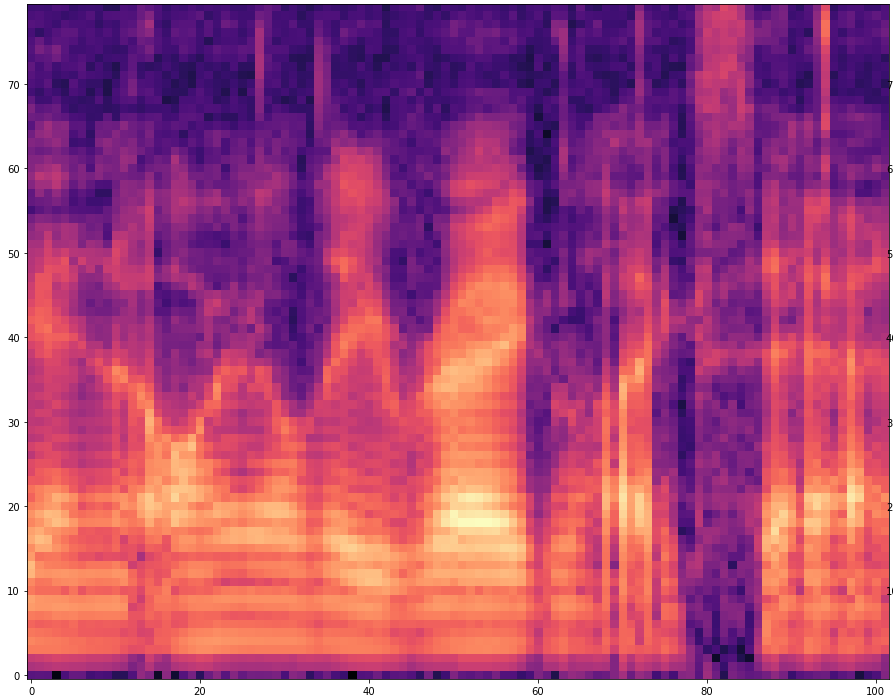 | 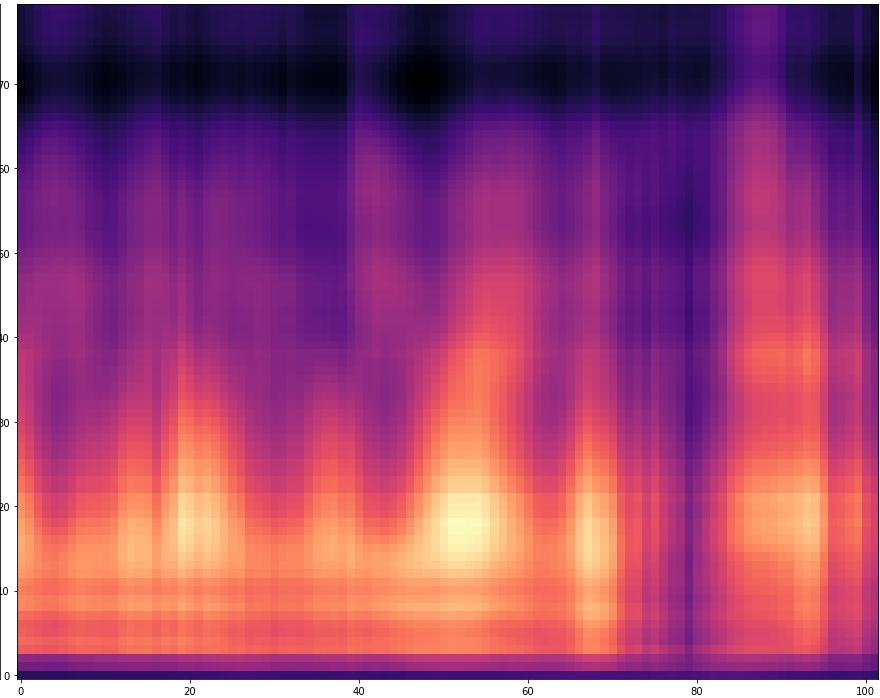 | |
| 10 | 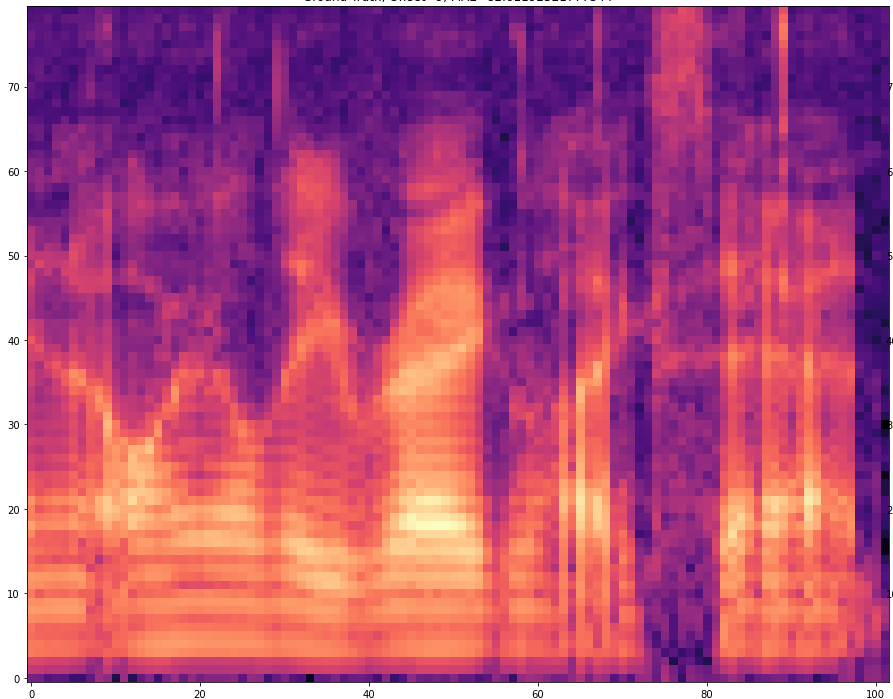 | 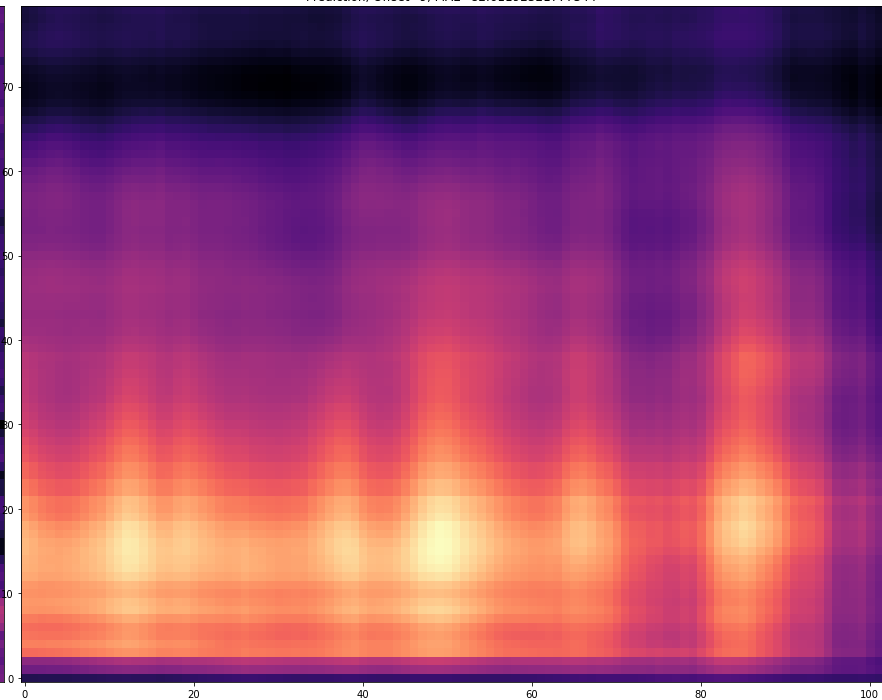 | |
| 20 | 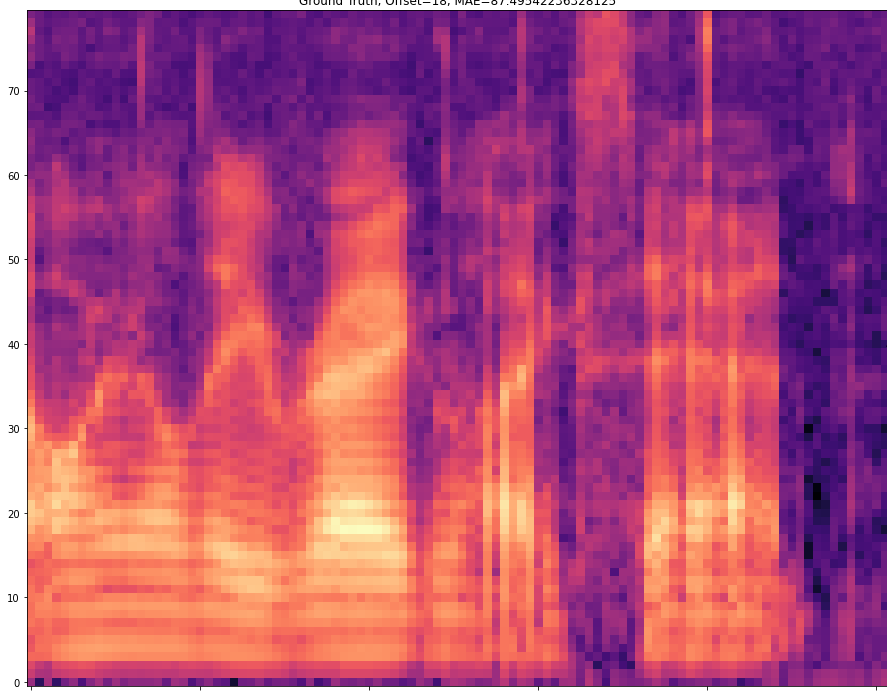 | 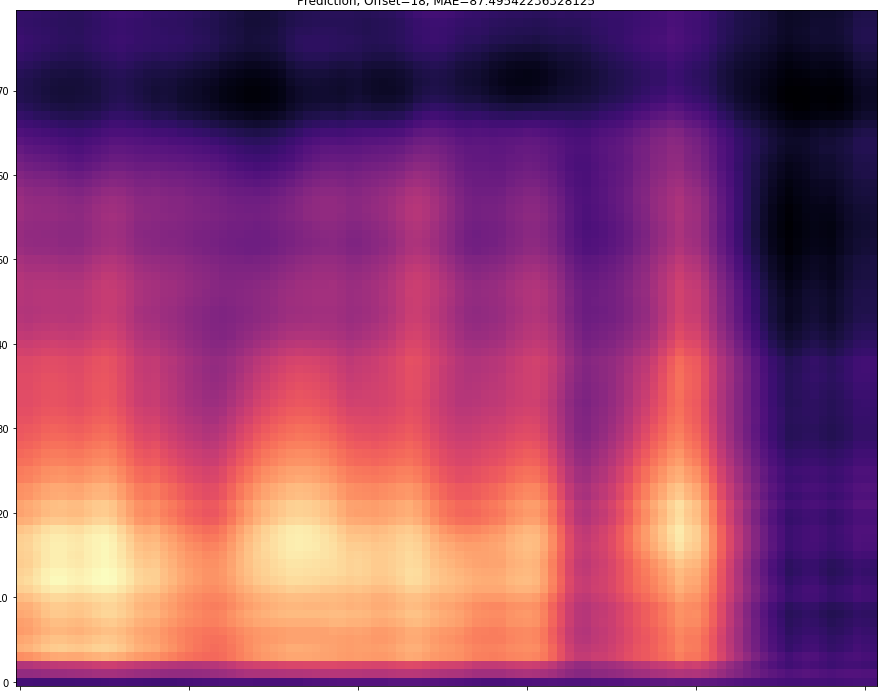 | |
| 25 | 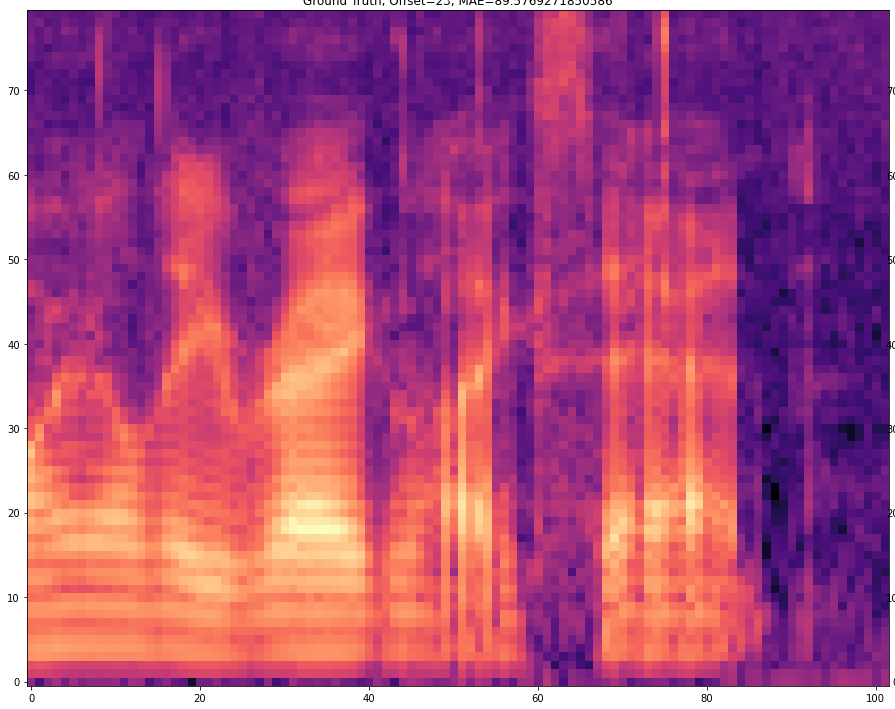 | 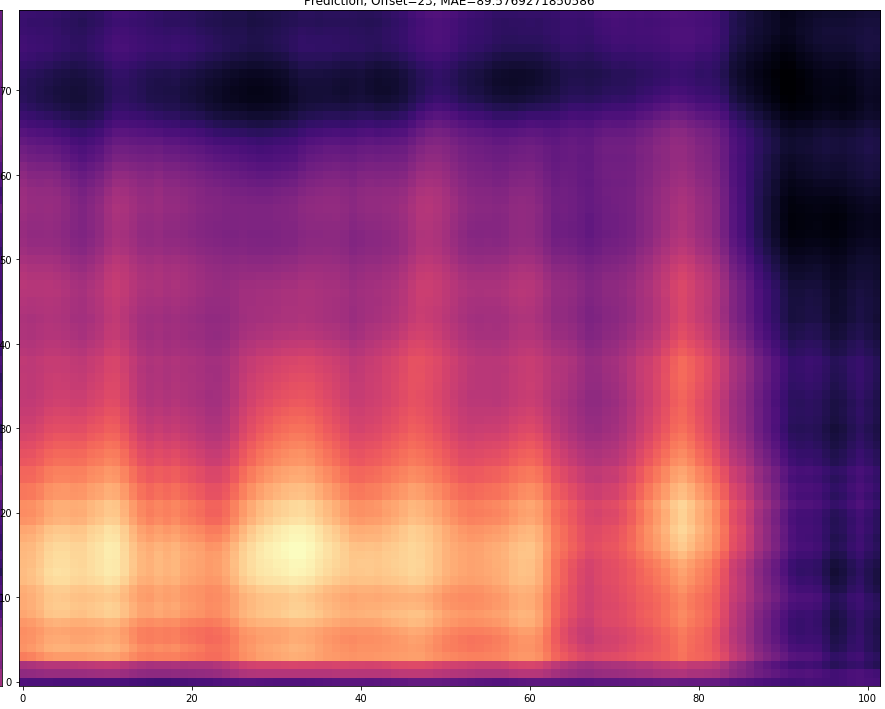 |
Speaker FJLM0, Sentence SA2 (Overfitted Model)
This model overfitted on the test data - but is for some sentences (such as this one) particularly good
Ground truth audio (resynthesized Mel-spectrogram):
offset | Ground Truth spectrogram | Predicted Spectrogram | Predicted Audio |
|---|---|---|---|
| 1 | /1-ahead_gt.png) | /1-ahead.png) | |
| 5 | /5-ahead_gt.png) | /5-ahead.png) | |
| 10 | /10-ahead_gt.png) | /10-ahead.png) | |
| 20 | /20-ahead_gt.png) | /20-ahead.png) | |
| 25 | /25-ahead_gt.png) | /25-ahead.png) |