import torch
import platform
import torchaudio
import matplotlib.pyplot as plt
import IPython.display as ipd
import warnings
warnings.filterwarnings('ignore')
if platform.system() == "Windows":
torchaudio.USE_SOUNDFILE_LEGACY_INTERFACE = False
torchaudio.set_audio_backend("soundfile")
else:
torchaudio.set_audio_backend("sox_io")
def plot_spectro(spectro):
plt.figure(figsize=(20, 10))
plt.imshow(spectro.squeeze(), origin="lower", cmap=plt.get_cmap("magma"))
plt.tight_layout()
plt.show()
Load Audio File
Load audio file into torch.Tensor object.
Reference: https://pytorch.org/audio/stable/torchaudio.html#i-o-functionalities
file_path = 'D:/Projekte/temporal-speech-context/data/TIMIT/MJTH0/SA1.WAV'
waveform = torchaudio.load(file_path)[0]
Convert to Mel-Spectrogram
Create MelSpectrogram for a raw audio signal. This function is a composition of Spectrogram and MelScale.
Reference: https://pytorch.org/audio/stable/transforms.html#melspectrogram
mel_spectro_transform = torchaudio.transforms.MelSpectrogram(sample_rate=16000,
win_length=400,
hop_length=200,
n_fft=512,
f_min=0,
f_max=8000,
n_mels=80,
)
mel_spectro = mel_spectro_transform(waveform)
Plot Mel-Spectrogram
plot_spectro(mel_spectro)
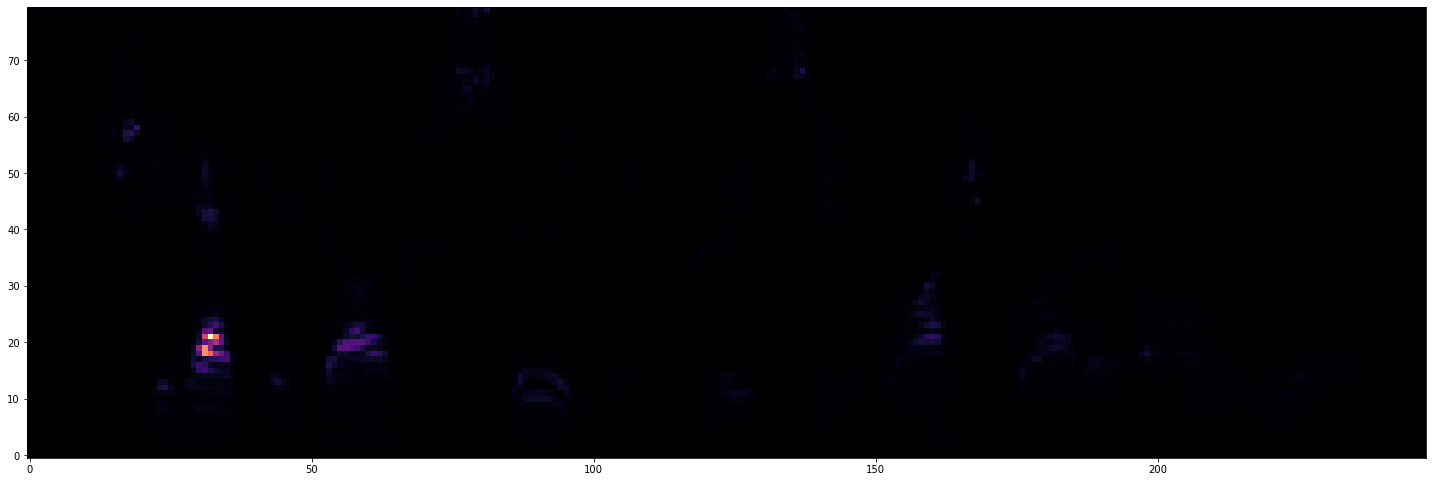
Transform to DB-scale
Turn a tensor from the power/amplitude scale to the decibel scale. (This form of the spectrogram is what is fed into the model)
Reference: https://pytorch.org/audio/stable/transforms.html#amplitudetodb
db_transform = torchaudio.transforms.AmplitudeToDB()
mel_spectro_db = db_transform(mel_spectro)
Plot DB-scale Mel-Spectrogram
plot_spectro(mel_spectro_db)
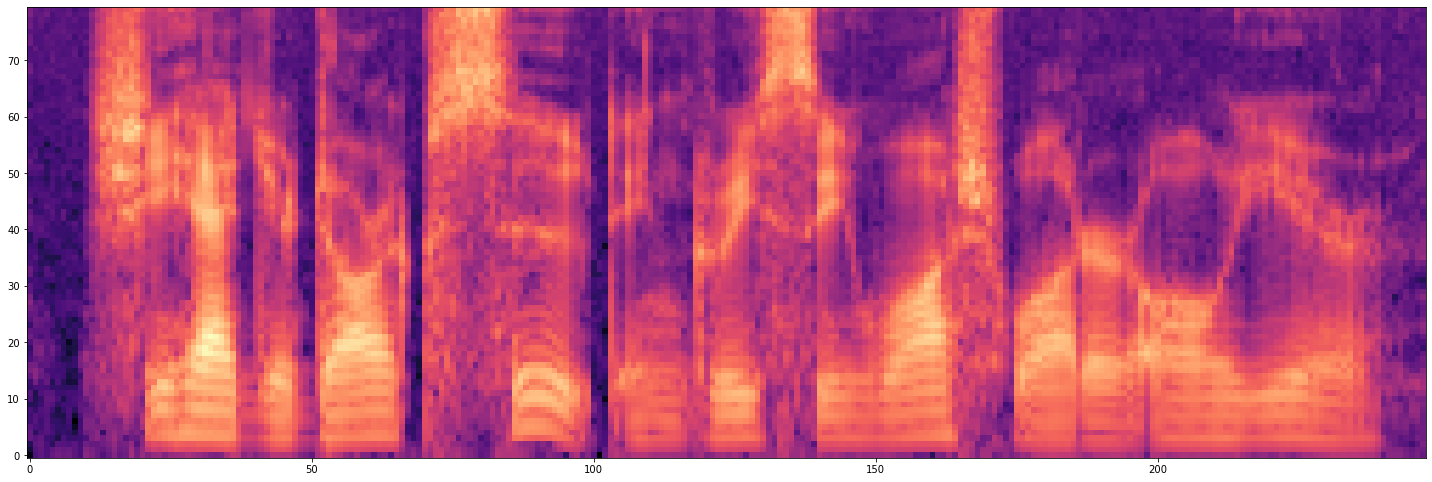
Convert Mel-Spectrogram to Waveform
From DB-scale to Ampltiude
# The torchaudio library contains only a transformation AmplitudeToDB but not a function DBToAmplitude
# Therefore, directly access functional library
from torchaudio import functional as F
class DBToAmplitude(torch.nn.Module):
def __init__(self):
super(DBToAmplitude, self).__init__()
self.ref = 1
self.power = 1
def forward(self, x):
return F.DB_to_amplitude(x, self.ref, self.power)
db_to_amplitude_transform = DBToAmplitude()
mel_spectro_recon = db_to_amplitude_transform(mel_spectro_db)
print("Reconstruction seems to be {}".format("correct" if torch.allclose(mel_spectro_recon, mel_spectro) else "wrong"))
Reconstruction seems to be correct
Inverse Mel-Spectrogram
Reference: https://pytorch.org/audio/stable/transforms.html#inversemelscale
inverse_mel = torchaudio.transforms.InverseMelScale(n_stft=257, n_mels=80, sample_rate=16000, f_min=0.0, f_max=8000)
spectro_recon = inverse_mel(mel_spectro_recon)
Apply Griffin-Lim
griffin_lim = torchaudio.transforms.GriffinLim(n_fft=512, win_length=400, hop_length=200)
waveform_recon = griffin_lim(spectro_recon)
Compare Original and Reconstructed Waveform
plt.figure(figsize=(20, 10))
plt.plot(waveform.T, label="original", alpha=.7)
plt.plot(waveform_recon.T, label="Re-Synthesized", alpha=.7)
plt.legend()
plt.tight_layout()
plt.show()
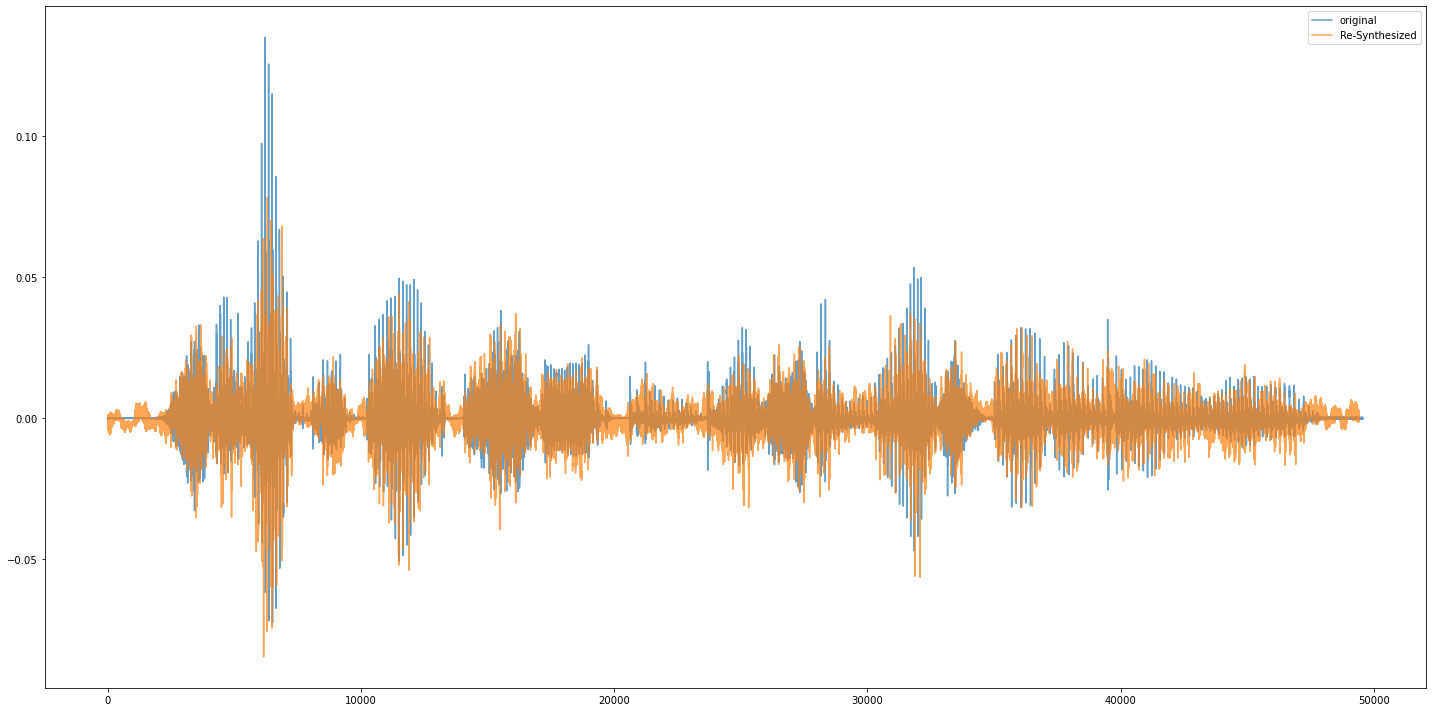
Play Audio
print("Original:")
ipd.display(ipd.Audio(waveform, rate=16000))
print("Re-Synthesized:")
ipd.display(ipd.Audio(waveform_recon, rate=16000))
Original:
Re-Synthesized:
Convert Mel-Spectrogram to Waveform Using Librosa Library
from librosa.feature.inverse import mel_to_audio
waveform_recon_lib = mel_to_audio(mel_spectro_recon[0].numpy() * 0.1, hop_length=200, sr=16000, n_fft=512)
plt.figure(figsize=(20, 10))
plt.plot(waveform.T, label="Original", alpha=.7)
plt.plot(waveform_recon_lib.T, label="Reconstructed", alpha=.7)
plt.legend()
plt.tight_layout()
plt.show()
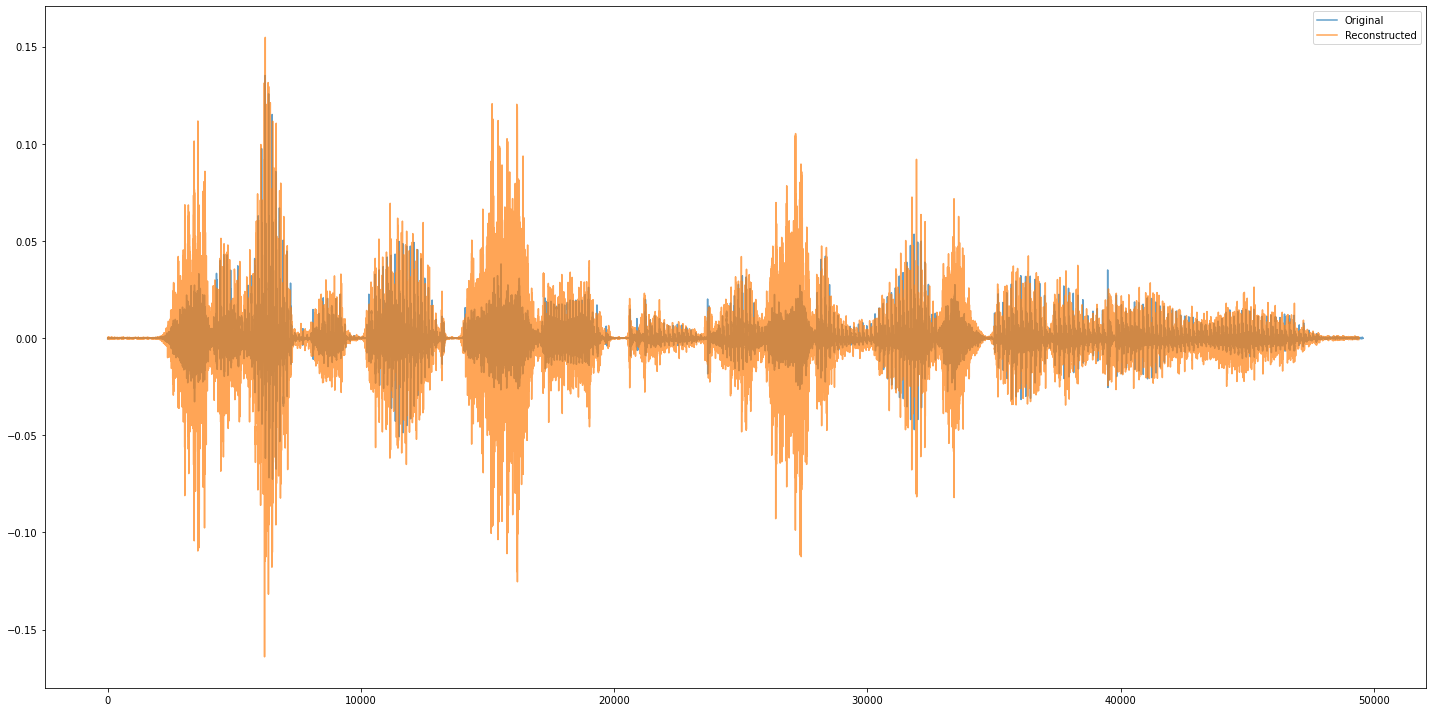
print("Original:")
ipd.display(ipd.Audio(waveform, rate=16000))
print("Re-Synthesized (Librosa):")
ipd.display(ipd.Audio(waveform_recon_lib, rate=16000))
Original:
Re-Synthesized (Librosa):